
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- 티스토리챌린지
- 입출력
- 오버라이딩
- 프로그래머스
- 멀티프로세싱
- LocalDate
- SQL Mapper
- 둘만의 암호 자바
- 백트래킹
- spring security
- java
- spring security 설정
- 혼공얄코
- BFS
- 자바의 정석
- 다형성
- StringBuffer
- 리눅스
- over()
- 오블완
- hackerrank
- 프로그래머스 둘만의 암호
- 캡슐화
- 멀티태스킹
- 오버로딩
- localtime
- 자바의정석
- 둘만의 암호
- CPU
- StringBuilder
- Today
- Total
쉽게 쉽게
변수 본문
이 글은 '자바의 정석'의 내용을 기반으로 공부한 내용을 덧붙인 글입니다.
1. 변수란?
"단 하나의 값을 저장할 수 있는 메모리 공간"
2. 변수의 명명규칙
(1) 대소문자는 구분되며, 길이에 제한이 없다.
(2) 예약어를 사용해서는 안된다.
(3) 숫자로 시작해서는 안된다.
(4) 특수문자는 '_'와 '$'만 허용된다.
예약어란?
프로그래밍언어의 구문에 사용되는 단어
ex) public, do, default, return, true 등등
★ 권장되는 명명 규칙 방법
(1) 클래스 이름의 첫 글자는 항상 대문자로 한다.(파스칼 케이스)
단 변수와 메서드의 이름의 첫 글자는 소문자로 한다.(카멜 케이스)
(2) 여러 단어로 이루어진 이름은 단어의 첫 글자를 대문자로 한다.
ex) lastIndexOf, StringBuffer
(3) 상수의 이름은 모두 대문자로 한다. 여러 단어로 이루어진 경우 '_'로 구분한다.(스네이크 케이스)
ex) PI, MAX_NUMBER
프로그램 네이밍 규칙 종류에 대해 알고 싶으면 아래를 클릭하세요.
★ 프로그램 네이밍 규칙의 종류
(1) Camel Case(카멜 케이스)
낙타와 같이 문자열의 첫 문자를 제외하고 단어의 첫 글자마다 대문자로 표현하는 방식이다.
(혹이 있는 낙타의 이미지를 생각)
대부분의 프로그램이 카멜 케이스 형식을 따른다.
전 : My Variable Name
후 : myVariableName
(2) Pascal Case(파스칼 케이스)
카멜 케이스와 유사하지만 첫 문자도 대문자로 표현하는 방식이다.
전 : My Variable Name
후 : MyVariableName
(3) Kebab Case(케밥 케이스)
카멜 케이스와 달리 모두 소문자로 표현하며 단어와 단어 사이를 대시(-)를 이용하여 구분합니다.
스프링의 yml파일이나 url주소에서 사용된다.
전 : My Variable Name
후 : my-variable-name
(4) Snake Case(스네이크 케이스)
케밥의 대시(-)와 다르게 언더스코어(_)를 구분자로 한다.
모든 문자를 대문자로 나타내는 방식도 사용되며 주로 상수 표현 시에 사용된다.
전 : My Variable Name
후 : MY_VARIABLE_NAME
3. 변수의 타입
(1) 기본형 타입
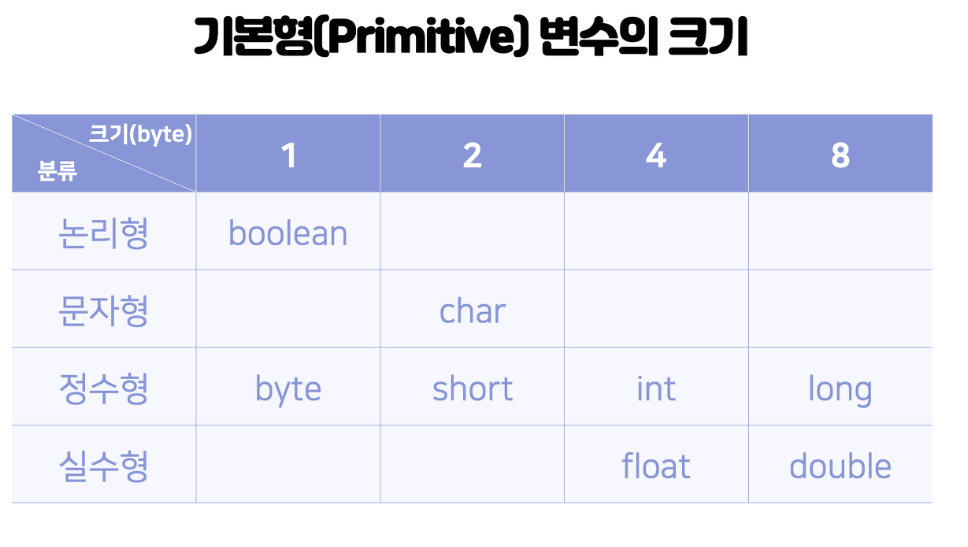
특징
- 실제 값을 저장
- 문자형 char는 내부적으로 정수(*유니코드)로 저장하기 때문에 정수형과 별반 다르지 않으며, 정수형 또는 실수형과 연산도 가능하다.
유니코드란?
아스키 코드(ASCII code)란, 미국 국립 표준 협회에서 영어 알파벳, 숫자, 구두점 등을 컴퓨터에서 표현하기 위해 표준화한 일종의 부호 체계이다. 아스키 코드는 7비트(128가지)로 이루어져 있으며, 각 문자에 대해 고유한 숫자 코드를 할당한다. 예를 들어, 대문자 'A'는 65, 소문자 'a'는 97의 아스키 코드 값을 가지며, 숫자 '0'은 48의 아스키 코드 값을 가진다. 이러한 아스키 코드는 컴퓨터에서 문자를 처리하고 저장하는 데 필수적이다.
그러나 아스키 코드의 가장 큰 한계점은 다양한 언어와 문자를 처리할 수 없다는 점이다. 인터넷이 발달되면서 서로 다른 문자 인코딩을 사용하는 컴퓨터 간의 문서교환에 어려움이 생겼다. 아스키 코드는 알파벳, 숫자, 구두점 등의 문자를 처리하는 데 탁월한 성능을 보이지만, 다른 언어의 문자나 기호 등은 표현할 수 없다. 예를 들어 한국어의 자음과 모음의 조합이나 중국어의 한자는 아스키 코드로 표현이 불가능하다.
(미국에서 만들었으니 영문에 효과적인게 당연해 보인다.)
이러한 어려움을 해소하고자 전 세계의 모든 문자를 하나의 통일된 문자집합으로 표현하고자 노력했고, 그것이 '유니코드'이다.
유니코드는 아스키 코드를 그대로 포함하고 있다.
유니코드는 다양한 문자를 처리하기 위해 1바이트에서부터 4바이트까지 다양한 바이트 수를 사용한다.
(아스키 코드는 2byte 이상 표현 불가)
일반적으로 유니코드 문자의 바이트 수는 다음과 같다.
UTF-8: 가변적으로 1바이트에서 4바이트까지 사용
UTF-16: 고정적으로 2바이트 또는 4바이트 사용
UTF-32: 고정적으로 4바이트 사용
UTF-8은 현재 가장 많이 사용되는 유니코드 인코딩 방식 중 하나로, 영어와 같은 ASCII 문자는 1바이트로 표현할 수 있고, 한국어나 중국어 같은 다국어 문자는 3바이트에서 4바이트까지 사용할 수 있다.
한글은 유니코드로 3바이트로 표현된다. 예를 들어, '가'라는 글자는 유니코드 상으로 U+AC00으로 표현되며, 이를 UTF-8로 인코딩하면 3바이트의 시퀀스인 0xEA 0xB0 0x80으로 표현된다.
UTF-16은 2바이트 또는 4바이트를 사용하며, 대부분의 문자를 2바이트로 표현할 수 있다.
UTF-32는 모든 문자를 4바이트로 표현하며, 다른 인코딩 방식보다 빠르게 문자를 처리할 수 있다.
- char ch = 'A'; //문자 'A'를 char타입의 변수 ch에 저장 실제로는 'A'가 아닌 유니코드가 저장된다. 문자 A의 유니코드는 65이므로 ch에는 65가 저장된다. char ch = 65; 와 char ch = 'A'; 는 동일한 결과를 나타낸다.
- 문자열을 처리할 때, char배열이 아닌 String클래스를 이용해서 문자열을 처리하는 이유는 "String클래스가 char배열에 여러 가지 기능을 추가하여 확장한 것" 이기 때문이다.
(4장 배열에서 정리) - boolean을 제외한 7개의 기본형은 서로 연산과 변환이 가능하다.
- 일반적으로 int를 많이 사용한다. 왜냐하면 int는 CPU가 가장 효율적으로 처리할 수 있는 타입이기 때문이다.
JVM의 피연산자 스택(stack)이 피연산자를 4 byte단위로 저장하기 때문에 크기가 4byte보다 작은 자료형의 값을 계산할 때는 4byte로 변환하여 연산을 수행한다.
(2) 참조형 타입
특징
- 객체의 주소를 저장한다.
- 자바의 특징에서 설명했듯이 변수는 타입에 따라 각각의 메모리 영역에 저장되는데, 스택(stack) 영역과 힙(heap) 영역에 기본형 타입과 참조형 타입을 각각 저장한다.
- 스택은 메서드 호출 시에 사용되는 메모리가 저장되는 공간으로, 실제 값을 가지는 기본형 변수를 저장한다.
- 힙은 객체와 배열 등을 저장하는 공간으로 객체를 참조하는 참조형 변수를 저장한다. 여기서 참조형 변수 자체는 스택 영역에 저장되지만, 실제 값은 힙에 새로운 공간을 만든 후 저장된다.
- 즉 실제 값은 힙 영역에 저장되고, 힙에 저장된 주소를 불러오는 주소 값이 스택 영역에 저장된다.
MyObject obj = new MyObject();- 예를 들어 MyObject라는 새로운 객체를 생성하면, 생성된 MyObject 객체는 힙 영역에 저장되고, obj는 해당 객체를 참조하게 된다. 즉 obj는 MyObject 객체의 주소값을 가진 상태로 스택 영역에 저장된다.
공부하면서 유용한 정보를 얻을 수 있던 글 입니다.
https://colossus-java-practice.tistory.com/7
[Chapter 1 변수] 7. 참조형 변수(Reference Variable)의 기본개념
우리가 지금까지 변수에 대해서 알아보면서 중점적으로 건드렸던 것은 변수 중에서도 기본형 변수(Primitive Variable)였다. 그런데 앞서 변수의 타입에 대해서 알아볼 때 우리가 배우는 자바(Java)에
colossus-java-practice.tistory.com
| 잘못된 내용이 있다면 지적부탁드립니다. 방문해주셔서 감사합니다. |

'Java > Java' 카테고리의 다른 글
| 객체지향언어(캡슐화, 다형성) (1) | 2023.03.17 |
|---|---|
| 객체지향언어(특징, 추상화, 상속) (1) | 2023.03.16 |
| [Java] 배열 (1) | 2023.03.14 |
| 연산자 (0) | 2023.03.14 |
| 자바의 특징 (1) | 2023.03.12 |



